Diversity and Innovation in Concordance Organization and Interpretation: Workshop at ICAME45
Diversity and Innovation in Concordance Organization and Interpretation: Workshop at ICAME45
Author: Alexander Piperski
Published: Posted on 2 July 2024
Concordance reading is a cornerstone of corpus linguistics, facilitating in-depth analysis and interpretation of linguistic data. This topic was the focus of a pre-workshop held on July 18, 2024, as part of the 45th ICAME conference in Vigo. The workshop, organized by the Reading Concordances in the 21st Century (RC21) project team, featured six presentations exploring various facets of concordancing.
Key Presentations and Insights
The RC21 team walked the audience through the key aspects of their project. Michaela Mahlberg and Natalie Finlayson’s talk, presented by Alexander Piperski, examined the use of concordance reading in research papers. The authors identified three primary concordance reading strategies: selecting, ordering, and grouping. The presentation detailed variations of these strategies observed in a sample of 40 research papers from four different fields.
Stephanie Evert introduced a mathematical model of these strategies, which provides a framework for developing and combining computational algorithms. She advocated for a tree-like approach to document the process of concordance reading in a reproducible way. Alexander Piperski and Levi Dietsch demonstrated the implementation of these strategies and the analysis tree within the FlexiConc Python library, which will be publicly released in the autumn.
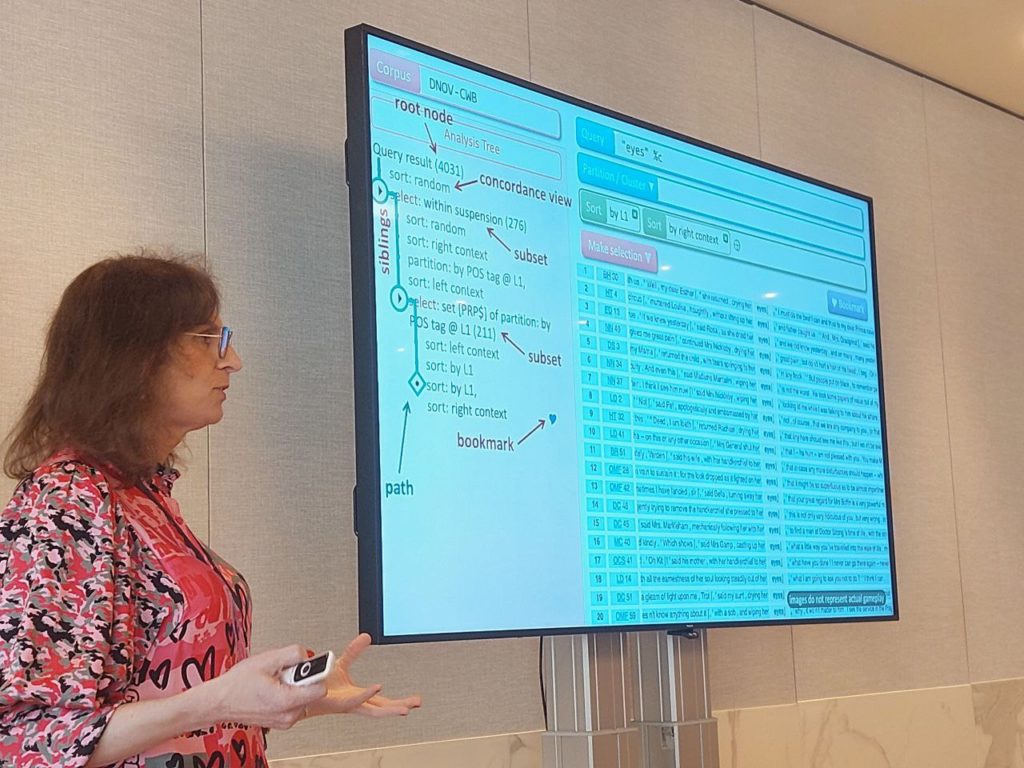

Mathew Gillings from Vienna University of Economics and Business addressed the interpretability of concordance lines. He demonstrated how “expanding the line” (i.e., looking at a larger context than visible on a single concordance line) is sometimes crucial for analysts to reach a clear interpretation, occasionally even reversing the initial labeling of examples.
Susan Hunston and Xin Susie Sui, from the University of Birmingham and Capital Normal University respectively, explored the use of Local Grammar and theoretical frameworks like FrameNet in reading concordances. They also highlighted terminological and conceptual differences between Units of Meaning and Constructions.
Laurence Anthony from Waseda University presented on the impact of word and sentence embeddings in corpus linguistics. He argued that these natural language processing techniques have the potential to revolutionize corpus querying by providing concordance lines that, while not exactly matching the query, are semantically related. He also showed how embeddings can be used to cluster concordance lines.



Workshop Discussion
The workshop concluded with a lively discussion moderated by Stephanie Evert. The dialogue underscored the balance between embracing user-friendly, one-button solutions like Google search and ChatGPT and maintaining the in-depth understanding, reproducibility, and accountability essential to corpus linguistics. The participants were all keen that the core principles of reproducibility and accountability should be upheld and supported by corpus management tools.